After the execution of the GATE controller a set of syntactical annotations are returned associated with the input query. Annotations include information about sentences, tokens, nouns and verbs. For example, we get voice and tense for the verbs, or categories for the nouns, such as determinant, singular/plural, conjunction, possessive, determiner, preposition, existential, wh-determiner, etc. When developing AquaLog we extended the set of annotations returned by GATE, by identifying terms, relations, question indicators (which/who/when. etc.) and patterns or types of questions. This is achieved through the use of Jape grammars, which consist of a set of phases, that run sequentially, and each phase is defined as a set of pattern rules, which allow us to recognize regular expressions using previous annotations in documents. In other words, its power lies in the ability of regarding the data store in annotation graphs in GATE as simple sequences, which can be matched deterministically by using regular expressions
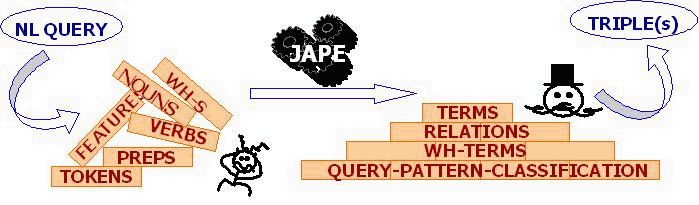
A key feature is the natural language scalability of the Linguistic components in AquaLog due to these regular expressions; in other words, extending the set of NL recognized by AquaLog is done through the use of regular expression in a text file
Examples of the linguistic categories recognized until now are in the Examples section . The categories tell to the RSS the kind of solution that needs to be achieved, and also gives an indication to the Linguistic Component about how to create the Query-Triple.
The classification of the queries in AquaLog is achieved based on two main different groups of queries, the basic queries which are translated into just one Query-Triple whereas the combination of queries are translated into two Query-Triples.
It is important to emphasize that at this stage all the terms are strings or an array of strings without any correspondence with the ontology as the analysis is completely domain independent and is entirely based on the natural language features for English. The Query-Triple is only a formal, simplified way of representing the NL-query, so when a Query-Triple is mapped over an Onto-Triple or various Onto-Triples, the category of the triple can be modified to represent the statements in the ontology appropriately. We can only deal with a subset of natural language but the architecture presented makes it possible to extend this subset in a relatively easy way.
 |
 |
 |
 |