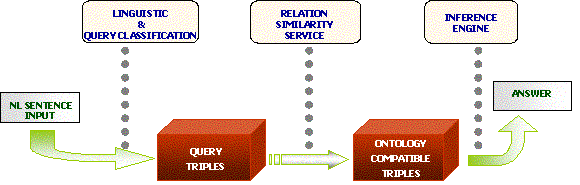
The main aim of the Linguistic component is to categorize and translate the NL input query into a set of intermediate representation based on triples, which are referred to as the Query-Triples.
The RSS component takes as an input these Query-Triples and further processes them to produce the ontology-compliant queries, called Onto-Triples.
AquaLog data model is triple-based .
The main challenge in the development of the current version of AquaLog is to efficiently deal with complex NL queries in which: (1) more than one/two terms may be present on a query; (2) a query may have more than one explicit relation; (3) a query may contain implicit relations, which can take the form of clauses or prepositions between terms; (4) query terms can be mapped to instances, classes, values or the combination of them, in compliance with the ontology to which it subscribes to; (5) query relations can be mapped to a concept or to a one or few relations on an ontology; the name used in the relations may be completly different. Moreover, these queries add another layer of complexity mainly due to their ambiguous nature, such type of linguistic ambiguity in an intrinsic property of the natural language.
AquaLog is a portable system designed with the aim of making our system as flexible and as modular as possible. It is implemented in Java as a web application, using client-server architecture. A key feature of AquaLog is the use of a plug-in mechanism , which allows AquaLog to be configured for different KR languages. Currently we subscribe to the Operational Conceptual Modelling Language( OCML), using our own OCML-based KR infrastructure . However, in future our aim is also to provide direct plug-in mechanisms for the emerging RDF and OWL servers.
String algorithms are used to find the patterns in the ontology for any of the terms inside the intermediate triples obtained from the user's query. They are based on String Distance Metrics for Name-Matching Tasks, using an open-source from the Carnegie Mellon University in Pittsburgh. This comprises a number of string distance metrics proposed by different communities, including edit-distance metrics, fast heuristic string comparators, token-based distance metrics, and hybrid methods. After experimental comparisons, using the KMi ontology with different metrics, AquaLog makes use of a combination of the following metrics: JaroWinkler, Level2JaroWinkler and Jaro.
Try AquaLog demo! (no longer available)
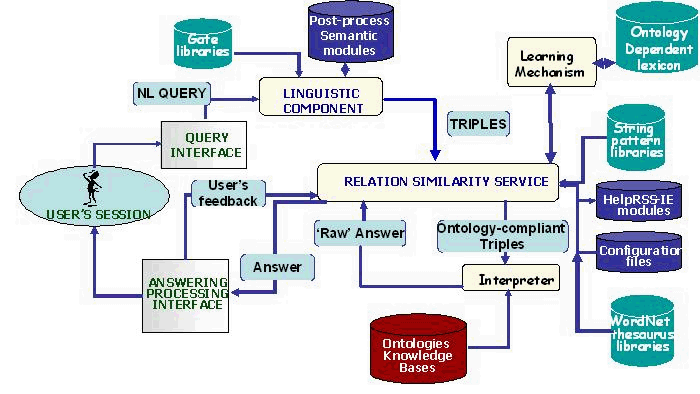
 |
 |
 |
 |